Vector Databases Explained

To understand vector databases, it’s best to start by knowing what sort of search does it empower. In a typical scalar-based database, we adapt to keyword-based search or query-based search. The search query is matched across rows of data and the matching records are sent back as a result.
With vector database, one can perform a semantic search which uses context to proceed with search query processing. Unlike traditional keyword-based search, semantic search is performed to understand the meaning of what is being asked.
Examples of Semantic search
Java bean’s color
Java beans release date
In the above statements, the system understands that the first one is talking about the coffee bean whereas the second one is talking about software programming. The context or meaning plays a vital role in what the search results should be and this knowledge is what decides the retrieval of results.
Let’s dive deeper and understand how the search happens.
To perform a semantic search, each word or sentence is transformed into a set of numeric values called vectors. This text transformation called embeddings, makes it possible to conduct a search based on meaning & retrieve the right result.
As you remember, a vector is nothing but set of numbers in world of mathematics.
In the above example, the Java bean word is stored as a set of vectors with many associated properties :
Representation of java bean as coffee bean would look like this
java bean = [ color: 53, is_coffee: 1, released_on: 89, is_software:0]
Representation of Java Bean as software would look like this:
java bean = [ color: 0, is_coffee: 0, released_on: 96, is_software:1]
Let’s see it together

Just like how a word can be embedded, sentences can be embedded too into vector sets, which capture their meaning and thereby allow us to perform even mathematical operations on them.
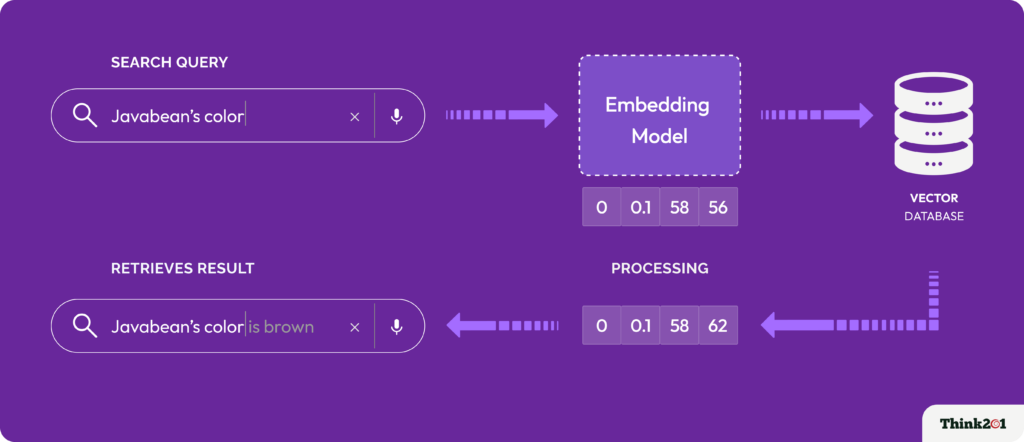
Now, when a search query is made, the query statement too is embedded into vector embeddings and results are retrieved based on the nearest match. There are various algorithms ( Co-sine similarity, LSH, HNSW) that make it so simple to explain but have core mathematical concepts at work.
Stepping back a bit. Who does the embedding?
The large language models today are capable of doing the embeddings and this need not be a handmade effort.
Word2Vec, fastText, GloVe, BERT, GPT, ELMo, LSTM and so on.
You can adapt to models based on the use case and the generated vector embeddings get stored in a special database called vector database. These databases not only empower in storing these special data structures but also provide powerful algorithms to make the search easy & efficient.
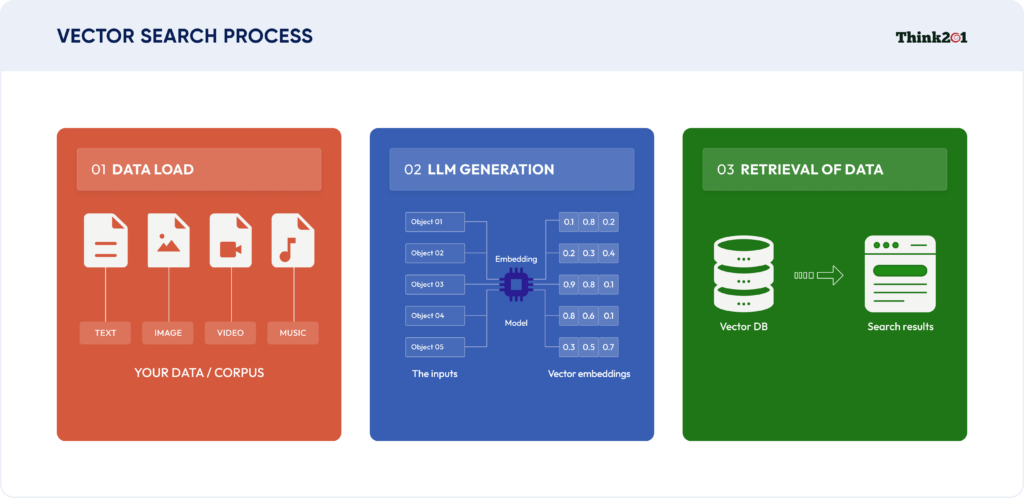
Visual Representation of How Vector Search Happens
Available Vector Databases
The following are a few of our choices when it comes to vector databases
PineCone | QDrant | ChromaDB | ClickHouse
The choice of the vector database can vary depending on the need and specification of the product.
That’s a brief about vector databases and the concept. Watch out this space for more such articles on AI and its concepts.